In an earlier post,
I had mentioned the need for comparing graphs for different
applications and described the spectral graph distance for the said
purpose. In this post, we are going to consider two other graph distance
measures. The first measure is called DeltaCon measure. This measure
works under the assumption that the node correspondence between the two
graphs is known. The second measure is known as the Portrait Divergence
and can be used for any graph pair. In addition to these two measures,
there are a few other measures that are available. It turns out that
most measures yield highly correlated results; thus knowing 2-3
different measures is a good starting point to explore other measures as
well as the applications where such measures are used.
DeltaCon Measure of Graph Similarity
The basic idea behind this method is to calculate an affinity measure
between a pair of nodes in the first graph, repeat the similar affinity
calculations for the corresponding node pair in the second graph, and
then compare the two measures to get an idea about the difference in the
node pairs over two graphs. By repeating the node affinity calculations
over all node pairs for the respective graphs, one can get an aggregate
measure for similarity between the two graphs. The pairwise node
affinity  between node I and node j is measured by looking at all possible paths between the two nodes. The DeltaCon paper shows that the similarity matrix
between node I and node j is measured by looking at all possible paths between the two nodes. The DeltaCon paper shows that the similarity matrix  of a graph
of a graph  measuring the similarity between different node pairs can be obtained by the following expression:
measuring the similarity between different node pairs can be obtained by the following expression:
![S = [s_{ij}] = [I + \epsilon^2 D - \epsilon A]^{-1}](https://s0.wp.com/latex.php?latex=S+%3D+%5Bs_%7Bij%7D%5D+%3D+%5BI+%2B+%5Cepsilon%5E2+D+-+%5Cepsilon+A%5D%5E%7B-1%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
,
where  is an identity matrix,
is an identity matrix,  is the degree matrix, and
is the degree matrix, and  is the adjacent matrix of the graph . The quantity
is the adjacent matrix of the graph . The quantity  is a small positive constant.Given two graphs
is a small positive constant.Given two graphs  and
and 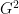 , the DeltaCon distance measure is computed using the following relationship:
, the DeltaCon distance measure is computed using the following relationship:
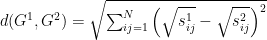
While the two similarity matrices can be compared using some other
difference measure, the above DeltaCon measure is a true metric
satisfying the triangular inequality of a true distance.
Illustration of DeltaCon Measure
Let’s use DeltaCon measure to compute distances between a set of graphs. We will do this using the netrd library which
provides a NetworkX-based interface to compute various graph distances
along with many other graph utilities. We will use the Air Transportation Multiplex Dataset
for experimentation. The dataset is composed of a multiplex network
composed of the airlines operating in Europe. It contains thirty-seven
different layers of networks each one corresponding to a different
airline. We will use only two subsets of the dataset consisting of the
three biggest major airlines (Air France, British Airways, and
Lufthansa), and the three low-cost airlines (Air Berlin, Easy Jet, and
Ryanair). A graph of the Ryanair is shown below; it consists of 149
nodes with 729 edges.
 |
| Ryanair Network |
All the nodes in the dataset have an associated airport code and node
indices are consistent over the entire multiplex. Thus, the node
correspondence exists in the dataset. However, each airline flies to
only a subset of the total nodes in the multiplex. Since DeltaCon
requires node correspondence as well the same number of nodes in the two
graphs to compare, we need to add nodes to the graphs under comparison
to bring them to same size. The following code snippet shows how the
DeltaCon distance is being computed for a pair of airlines; similar
computation applies to other airline pairs.
import numpy as np
import networkx as nx
import netrd
f = nx.read_adjlist(France.txt)
Fr = nx.Graph(f)
b = nx.read_adjlist(Brit.txt)
Br = nx.Graph(b)
list1 = list(Fr.nodes)
list2 = list(Br.nodes)
new_list1=set(list1)-set(list2)#Elements of list 1 that are not present in list 2
new_list2=set(list2)-set(list1)#Elements of list 2 that are not present in list 1
Fr.add_nodes_from(new_list2)
Br.add_nodes_from(new_list1)
# Now both graphs have identical size and nodes are in correspondence
dist = netrd.distance.DeltaCon()
print(dist(Fr,Br))
1.5233983011182537
The figure below shows the distances between the networks of different airlines calculated using the DeltaCon measure. I applied the single linkage clustering to the resulting distance. The result shown below in the form a dendrogram puts the three major airlines in one cluster and the three low-cost airlines in another cluster. This suggests that the DeltaCon distance is able to capture the underlying properties of a graph and can be used for graph discrimination.
 |
Distance matrix and Dendrogram by using DeltaCon
|
Portrait Divergence
This measure is based upon a matrix, called network portrait, which captures the distribution of shortest path lengths in a graph. The elements of the network portrait matrix $B$ for a graph with N nodes are defined as
$b_{j,k} \equiv \text{the number of nodes who have k nodes at distance j}$,
$ \text{ for } 0 ≤ j ≤ D \text{ and } 0 ≤ k ≤ N − 1$. The distance is taken as the shortest path length and D refers to the graph diameter(length of the longest shortest path). The network portrait provides a concise topological summary of a graph and has the graph invariant property, and thus can be used for comparing two networks or graphs.
The portrait divergence measure is computed by treating the rows of the network portrait matrix B as probability distributions. These probability distributions are combined to create a single joint distribution for all rows. Given two graphs, the corresponding distributions are then compared using the Jensen-Shanon divergence measure to produce a similarity value in the range of 0-1. Please see for details.
Let’s see if the results given by this method are different from above
or not by applying the portrait divergence measure to the airlines data.
The results are shown below; these are similar and yield two similar
clusters.
 |
Distance matrix and Dendrogram by using Portrait Divergence
|
Takeaway
I have discussed only three methods for graph comparison, spectral graph distance (in an earlier blog post) and the two discussed in this post. The DeltaCon method requires prior knowledge about the graphs in terms of node to node mappings over the graph pair being compared. The spectral graph distance and the portrait divergence methods do not have any such requirement. As I indicated earlier, there are a few other distance measures for graph comparison; however all these measures yield correlated results. I suggest looking at this paper if you get interested in this topic as a result of this post.

