Pre-trained large language models (LLMs) are being used for numerous natural language processing applications. These models perform well out of the box and are fine-tuned for any desired down-stream application. However, fine-tuning these models to adapt to specific tasks often poses challenges due to their large parameter sizes. To address this, a technique called Low Rank Adaptation (LoRA) has emerged, enabling efficient fine-tuning of LLMs. In this post, we will try to understand LoRA, and delve into its importance and application in fine-tuning LLMs. We will begin our journey by first looking at the concept of rank of a matrix, followed by a look at matrix factorization, and then to LoRA.
Rank of a Matrix
The rank of a matrix indicates the number of independent rows or column in the matrix. As an example, consider the following 4x4 matrix A:
A = [[2, 4, 6, 8], [1, 3, 5, 7], [4, 8, 12, 16], [3, 9, 15, 21]]
Looking at the first and third row of this matrix, we see that the third row is just a scale up version of the first row by a factor of 2. The same is true for the second and fourth rows. Thus, the rank of matrix A is 2 as there are only two independent rows.
The rank of a matrix of size mxn cannot be greater than min{m,n}. In other words, the rank of a matrix cannot be greater than the smallest dimension of the matrix. We say a matrix is a full rank matrix if its rank equals the largest possible rank for that matrix.
When a matrix is not a full rank matrix, it tells us that the underlying matrix has some redundancy in it that can be exploited for data compression or dimensionality reduction. This is done by obtaining a low-rank approximation of the matrix. The process of obtaining a low-rank approximation of a matrix is involves matrix factorization. Some of these factorization methods are briefly described below.
Matrix Factorization
Matrix factorization is the process of decomposing a matrix into multiple factors. Some of the matrix factorization are:
1. Singular Value Decomposition (SVD)
In SVD, a real-valued matrix A of size m x n is factorized as $ A = UDV^t$, where 𝐔 is an orthogonal matrix of size m x m of left singular vectors and 𝐕 is an orthogonal matrix of size n x n of right singular vectors. The matrix 𝐃 is a diagonal matrix of size m x n of singular values. A low rank approximation to matrix A of rank r is obtained by using only a subset of singular values and the corresponding left and right singular vectors as given by the following expression. In other words, the approximation is obtained by the weighted sum of rank one matrices.
$ \hat{ \bf A} = \sum\limits_{j=1}\limits^{k} d_{jj}\bf U_j\bf V^t,\text{ }k\leq r$
SVD is a popular matrix factorization method that is commonly used for data compression and dimensionality reduction. It has also been used for compressing convolutional neural networks. You can read more about SVD and its use for compression at this blog post.
2. Principal Component Analysis (PCA)
PCA aims to find the principal components that capture the most significant variance in the data. It works with data matrices that have been normalized to have zero mean. Let's say $X$ of m rows and n columns is one such data matrix where each row represents an observation vector of n features. PCA computes the eigenvalues and eigenvectors of the covariance matrix $C = \frac{1}{(1-n)}XX^t$ by factorizing it as $\frac{1}{(1-n)}WD^tW$, where $W$ is an orthogonal matrix of eigenvectors and $D$ is the diagonal matrix of eigenvalues. PCA is a popular technique for dimensionality reduction.
3. Non-Negative Matrix Factorization (NMF)
NMF is another technique for obtaining low rank representation of matrices with non-negative or positive elements. Given a data matrix $A$ of m rows and n columns with each and every element $a_{ij} ≥ 0$, NMF seeks matrices $W$ and $H$ of size m rows and k columns, and k rows and n columns, respectively, such that $A≈WH$, and every element of matrices $W$ and $H$ is either zero or positive. The value of k is set by the user and is required to be equal or less than the smallest of m and n. The matrix $W$ is generally called the basis matrix, and $H$ is known as expansion or coefficient matrix. The underlying idea of this terminology is that a given data matrix $A$ can be expressed in terms of summation of k basis vectors (columns of $W$) multiplied by the corresponding coefficients (columns of $H$). Compared to SVD, the NMF based factorization offers a better interpretation of the original data matrix as it is represented/approximated as a sum of positive matrices/vectors. NMF has been used to perform document clustering, making recommendations, visual pattern recognition such as face recognition, gene expression analysis, feature extraction, source separation etc. Basically, it can be used in any application where data matrix $A$ has no negative elements. You can read more about NMF at this blog post.
Low Rank Adaptation (LoRA) of Large Language Models
The first thing to note is that LoRA doesn't perform a low rank approximation of the weight or parameter matrix; it rather modifies it by generating a new low rank matrix that captures the needed parameter changes as a result of the fine tuning the LLM. The pre-trained matrix $W$ is frozen while fine tuning and the weight changes are captured in a delta weight matrix $\Delta W$ through gradient learning. The delta weight change matrix is a low rank matrix which is set as a product of two small matrices, i.e. $\Delta W = AB$. The $A$ matrix is initialized with values coming from a gaussian distribution while $B$ matrix is initialized with elements all equal to zero. This ensures that the pre-trained weights matrix is the only contributing matrix at the start of fine tuning. The figure below illustrates this setup for LoRA.
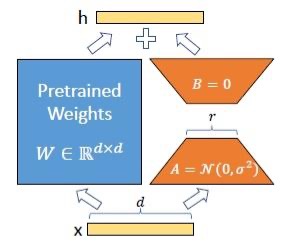 |
| LoRA Scheme: Matrix W is kept fixed and only A and B are trained. |
Let's now try to understand the reasoning behind LoRA and its advantages. The main motivation is that the pretrained models are over-parameterized with low intrinsic dimensionality. Further, the authors of LoRA hypothesize that change in weights during model fine tuning also has a low intrinsic rank. Thus, it is suffice to use a low rank matrix to capture the weight changes during fine tuning. LoRA offers several advantages. First, it is possible to share the pretrained model for several downstream tasks with each task having its own LoRA model. This obviously saves storage needs as well as makes task switching easier. Second, LoRA makes the LLMs adaptation for different tasks easier and efficient. Third, it is easy to combine with other fine tuning methods, if desired. As an example of the parameter efficiency of LoRA, consider the pretrained matrix of size 200x400. To perform adaptation, let matrix $A$ be of size 200x8 and matrix $B$ be of size 8x400 giving rise to the delta weight change matrix of the desired size of 200x400. The number of parameters thus needed by LoRA is only 200*8+8*400 = 4800 as compared to the number of parameter, 200*400 = 80000, needed to adjust without LoRA.
An important consideration in using LoRA is the choice of the rank of the $\Delta W$ matrix. Choosing a smaller rank leads to a simpler low-rank matrix, which results in fewer parameters to learn during adaptation. However, the adaptation with a smaller rank $\Delta W$ may not lead to the desired performance. Thus, the rank choice offers a tradeoff that typically requires experimentation to get the best adaptation.
LoRA in PEFT
PEFT stands for a general parameter-efficient fine-tuning library from Huggins Face that includes LoRA as one of its techniques. The few lines of codes below illustrate its basic use.
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
In the above example, mt0-large model is being fine tuned for a sequence to sequence conversion task. The rank of the delta weight change is specified as 8. The model has 1.2 B parameters but LoRA needs only 2.36M parameters, 19% of the total parameters, to train. If we are to change the rank to 12, the number of trainable parameters increases to 3538944, 28.7% of the total parameters. Clearly, the choice of rank is an important consideration when using LoRA.
LoRA's performance has been evaluated against full fine tuning and other efficient techniques for parameter computation. LoRA has been found to generally outperforms other efficient fine tuning techniques by a significant margin while yielding comparable or better performance than full fine tuning.
To wrap up, LoRA is an efficient technique for fine tuning large pretrained models. It is poised to play an important role in fine tuning and customizing LLMs for numerous applications.
It would be my pleasure to hear your comments/suggestions to make this site more interesting.







