Graph classification focuses on assigning labels or categories to entire graphs or networks. Unlike traditional classification tasks that deal with individual data instances, graph classification considers the entire graph structure, including nodes, edges and their properties. A graph classifier uses a mapping function that can accurately predict the class or label of an unseen graph based on its structural properties. The mapping function is learned during training using supervised learning.
Why Do We Need Graph Classification?
The importance of graph classification lies in graph data being ubiquitous in today's interconnected world. Graph based methods including graph classification have emerged as methodology of choice in numerous applications across various domains, including:
1. Bioinformatics: Classifying protein-protein interaction networks or gene regulatory networks can provide insights into disease mechanisms and aid in drug discovery. In fact, the most well-known success story of graph neural networks is the discovery of antibiotics to treat drug-resistant diseases, widely reported in early 2020.
2. Social Network Analysis: Categorizing social networks can help identify communities, detect anomalies (e.g., fake accounts), and understand information diffusion patterns.
3. Cybersecurity: Classifying computer networks can assist in detecting malicious activities, identifying vulnerabilities, and preventing cyber attacks.
4. Chemistry: Classifying molecular graphs can aid in predicting chemical properties, synthesizing new compounds, and understanding chemical reactions.
How Do We Build a Graph Classifier?
There are two main approaches that we can use to build graph classifiers: kernel-based methods and neural network-based methods.
1. Kernel-based Methods:
These methods rely on defining similarity measures (kernels) between pairs of graphs, which capture their structural and topological properties. Popular kernel-based methods include the random walk kernel, the shortest-path kernel, and the Weisfeiler-Lehman kernel. Once the kernel is defined, traditional kernel-based machine learning algorithms, such as Support Vector Machines (SVMs), can be applied for classification.
2. Neural Network- based Methods:
These methods typically involve learning low-dimensional representations (embeddings) of the graphs through specialized neural network architectures, such as Graph Convolutional Networks (GCNs) and Graph Attention Networks (GATs). The learned embeddings capture the structural information of the graphs and can be used as input to standard classifiers, like feed-forward neural networks or logistic regression models. For details on GCNs and node embeddings, please visit my earlier post on graph convolutional networks.
Both kernel-based and neural network-based methods have their strengths and weaknesses, and the choice depends on factors such as the size and complexity of the graphs, the availability of labeled data, and computational resources. Given that graph neural networks are getting more mileage, we will complete this blog post by going over steps needed for building a GNN classifier.
Steps for Building a GNN Classifier
Dataset
We are going to use the MUTAG dataset which is part of the TUDatasets, an extensive collection of graph datasets and easily accessible in PyTorch Geometric library for building graph applications. The MUTAG dataset is a small dataset of 188 graphs representing two classes of graphs. Each graph node is characterized by seven features. Two of the example graphs from this dataset are shown below.
Two example graphs from MUTAG dataset
We will use 150 graphs for training and the remaining 38 for testing. The division into the training and test sets is done using the available utilities in the PyTorch Geometric.
Mini-Batching
Due to the smaller graph sizes in the dataset, mini-batching of graphs is a desirable step in graph classification for better utilization of GPU resources. The mini-batching is done by diagonally stacking adjacency matrices of the graphs in a batch to create a giant graph that acts as an input to the GNN for learning. The node features of the graphs are concatenated to form the corresponding giant node feature vector. The idea of mini-batching is illustrated below.
Illustration of mini-batching
Graph Classifier
We are going to use a three-stage classifier for this task. The first stage will consists of generating node embeddings using a message-passing graph convolutional network (GCN). The second stage is an embeddings aggregation stage. This stage is also known as the readout layer. The function of this stage is to aggregate node embeddings into a single vector. We will simply take the average of node embeddings to create readout vectors. PyTorch Geometric has a built-in function for this purpose operating at the mini-batch level that we will use. The final stage is the actual classifier that looks at mapped/readout vectors to learn classification rule. In the present case, we will simply use a linear thresholding classifier to perform binary classification. We need to specify a suitable loss function so that the network can be trained to learn the proper weights.
A complete implementation of all of the steps described above is available at this Colab notebook. The results show that training a GCN with three convolutional layers results in test accuracy of 76% in just a few epochs.
Takeaways Before You Leave
Graph Neural Networks (GNNs) offer ways to perform various graph-related prediction/classification tasks. We can use GNNs make predictions about nodes, for example designate a node as a friend or fraud. We can use them to predict whether a link should exist between a pair of nodes or not in social networks to make friends' suggestions. And of course, we can use GNNs to perform classification of entire graphs with applications mentioned earlier.
Another useful library for deep learning with graphs is Deep Graph Library (DGL). You can find a graph classifier implementation using DGL at the following link, if you like.
According to some estimates, the unstructured data accounts for about 90% of the data being
generated everyday. A large part of unstructured data consists of text in
the form of emails, news reports, social media postings, phone
transcripts, product reviews etc. Analyzing such data for pattern
discovery requires converting text to numeric representation in the form
of a vector using words as features. Such a representation is known as vector space model in information retrieval; in machine learning it is known as bag-of-words (BoW) model.
In this post, I will describe different text vectorizers from sklearn library. I will do this using a small corpus of four documents, shown below.
corpus = ['The sky is blue and beautiful',
'The king is old and the queen is beautiful',
'Love this beautiful blue sky',
'The beautiful queen and the old king']
CountVectorizer
The CountVectorizer is the simplest way of
converting text to vector. It tokenizes the documents to build a
vocabulary of the words present in the corpus and counts how often each
word from the vocabulary is present in each and every document in the
corpus. Thus, every document is represented by a vector whose size
equals the vocabulary size and entries in the vector for a particular
document show the count for words in that document. When the document
vectors are arranged as rows, the resulting matrix is called document-term matrix; it is a convenient way of representing a small corpus.
For our example corpus, the CountVectorizer produces the following representation.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
Doc_Term_Matrix = pd.DataFrame(X.toarray(),columns= vectorizer.get_feature_names())
Doc_Term_Matrix
The column headings are the word features arranged in alphabetical
order and row indices refer to documents in the corpus. In the present
example, the size of the resulting document-term matrix is 4×11, as
there are 4 documents in the example corpus and there are 11 distinct
words in the corpus. Since common words such as “is”, “the”, “this” etc
do not provide any indication about the document content, we can safely
remove such words by telling CountVectorizer to perform stop word
filtering as shown below.
Although the document-term matrix for our small corpus example
doesn’t have too many zeros, it is easy to conceive that for any large
corpus the resulting matrix will be a sparse matrix. Thus, internally
the sparse matrix representation is used to store document vectors.
N-gram Word Features
One issue with the bag of words representation is the loss of
context. The BoW representation just focuses on words presence in
isolation; it doesn’t use the neighboring words to build a more
meaningful representation. The CountVectorizer provides a way to
overcome this issue by allowing a vector representation using N-grams of
words. In such a model, N successive words are used as features. Thus,
in a bi-gram model, N = 2, two successive words will be used as features
in the vector representations of documents. The result of such a
vectorization for our small corpus example is shown below. Here the
parameter ngram_range = (1,2) tells the vectorizer to use two
successive words along with each single word as features for the
resulting vector representation.
It is obvious that while N-gram features provide context and
consequently better results in pattern discovery, it comes at the cost
of increased vector size.
TfidfVectorizer
Simply using the word count as a feature value of a word really
doesn’t reflect the importance of that word in a document. For example,
if a word is present frequently in all documents in a corpus, then its
count value in different documents is not helpful in discriminating
between different documents. On other hand, if a word is present only in
a few of documents, then its count value in those documents can help
discriminating them from the rest of the documents. Thus, the
importance of a word, i.e. its feature value, for a document not only
depends upon how often it is present in that document but also how is
its overall presence in the corpus. This notion of importance of a word in a document is captured by a scheme, known as the term frequency-inverse document frequency (tf-idf ) weighting scheme.
The term frequency is a ratio of the count of a word’s
occurrence in a document and the number of words in the document. Thus,
it is a normalized measure that takes into consideration the document
length. Let us show the count of word i in document j by . The document frequency of word i represents the number of documents in the corpus with word i in them. Let us represent document frequency for word i by . With N as the number of documents in the corpus, the tf-idf weight for word i in document j is computed by the following formula:
The sklearn library offers two ways to generate the tf-idf representations of documents. The TfidfTransformer transforms the count values produced by the CountVectorizer to tf-idf weights.
One thing to note is that the tf-idf weights are normalized so that
the resulting document vector is of unit length. You can easily check
this by squaring and adding the weight values along each row of the
document-term matrix; the resulting sum should be one. This sum
represents the squared length of the document vector.
HashingVectorizer
There are two main issues with the CountVectorizer and
TdidfVectorizer. First, the vocabulary size can grow so much so as not
to fit in the available memory for large corpus. In such a case, we need
two passes over data. If we were to distribute the vectorization task
to several computers, then we will need to synchronize vocabulary
building across computing nodes. The other issue arises in the context
of an online text classifier built using the count vectorizer, for
example spam classifier which needs to decide whether an incoming email
is spam or not. When such a classifier encounters words not in its
vocabulary, it ignores them. A spammer can take advantage of this by
deliberately misspelling words in its message which when ignored by the
spam filter will cause the spam message appear normal. The HashingVectorizer overcomes these limitations.
The HashingVectorizer is based on feature hashing, also known as the hashing trick.
Unlike the CountVectorizer where the index assigned to a word in the
document vector is determined by the alphabetical order of the word in
the vocabulary, the HashingVectorizer maintains no vocabulary
and determines the index of a word in an array of fixed size via
hashing. Since no vocabulary is maintained, the presence of new or
misspelled words doesn’t create any problem. Also the hashing is done on
the fly and memory need is diminshed.
You may recall that hashing is a way of converting a key into an address of a table, known as the hash table. As an example, consider the following hash function for a string s of length n:
$\text{hash(s)} = (s[0] + s[1] \cdot p +s[2]\cdot p^2 +\cdots + s[n-1] \cdot p^{n-1})\text{ mod }m$
The quantities p and m are chosen in practice to minimize collision and set the hash table size. Letting p = 31 and m = 1063,
both prime numbers, the above hash function will map the word “blue” to
location 493 in an array of size 1064 as per the calculations:
where letter b is replaced by 2, l by 12, and so on
based on their positions in the alphabet sequence. Similarly, the word
“king” will be hashed to location 114 although “king” comes later than
“blue” in alphabetical order.
The HashingVectorizer implemented in sklearn uses the Murmur3
hashing function which returns both positive and negative values. The
sign of the hashed value is used as the sign of the value stored in the
document-term matrix. By default, the size of the hash table is set to ;
however, you can specify the size if the corpus is not exceedingly
large. The result of applying HashingVectorizer to our example corpus is
shown below. You will note that the parameter n_features,
which determines the hash table size, is set to 6. This has been done to
show collisions since our corpus has 7 distinct words after filtering
stop words.
from sklearn.feature_extraction.text import HashingVectorizer
vectorizer = HashingVectorizer(n_features=6,norm = None,stop_words='english')
X = vectorizer.fit_transform(corpus)
Doc_Term_Matrix = pd.DataFrame(X.toarray())
Doc_Term_Matrix
You will note that column headings are integer numbers referring to
hash table locations. Also that hash table location indexed 5 shows the
presence of collisions. There are three words that are being hashed to
this location. These collisions disappear when the hash table size is
set to 8 which is more than the vocabulary size of 7. In this case, we
get the following document-term matrix.
The HashingVectorizer has a norm parameter that determines whether any normalization of the resulting vectors will be done or not. When norm is set to None
as done in the above, the resulting vectors are not normalized and the
vector entries, i.e. feature values, are all positive or negative
integers. When norm parameter is set to l1, the
feature values are normalized so as the sum of all feature values for
any document sums to positive/negative 1. In the case of our example
corpus, the result of using l1 norm will be as follows.
With norm set to l2, the HashingVectorizer
normalizes each document vector to unit length. With this setting, we
will get the following document-term matrix for our example corpus.
The HashingVectorizer is not without its drawbacks. First of all, you
cannot recover feature words from the hashed values and thus tf-idf
weighting cannot be applied. However, the inverse-document frequency
part of the tf-idf weighting can be still applied to the resulting
hashed vectors, if needed. The second issue is that of collision. To
avoid collisions, hash table size should be selected carefully. For very
large corpora, the hash table size of
or more seems to give good performance. While this size might appear
large, some comparative numbers illuminate the advantage of feature
hashing. For example, an email classifier
with hash table of size 4 million locations has been shown to perform
well on a well-known spam filtering dataset having 40 million unique
words extracted from 3.2 million emails. That is a ten times reduction
in the document vectors size.
To summarize different vectorizers, the TfidfVectorizer appears a
good choice and possibly the most popular choice for working with a
static corpus or even with a slowing changing corpus provided periodic
updating of the vocabulary and the classification model is not
problematic. On the other hand, the HashingVectorizer is the best choice
when working with a dynamic corpus or in an online setting.
Any machine learning model building task begins with a collection of data vectors wherein each vector consists of a fixed number of components. These components represent the measurements, known as attributes or features, deemed useful for the given machine learning task at hand. The number of components, i.e. the size of the vector, is termed as the dimensionality of the feature space. When the number of features is large, we are often interested in reducing their number to limit the number of training examples needed to strike a proper balance with the number of model parameters. One way to reduce the number of features is to look for a subset of original features via some suitable search technique. Another way to reduce the number of features or dimensionality is to map or transform the original features in to another feature space of smaller dimensionality. The Principal Component Analysis (PCA) is an example of this feature transformation approach where the new features are constructed by applying a linear transformation on the original set of features. The use of PCA does not require knowledge of the class labels associated with each data vector. Thus, PCA is characterized as a linear, unsupervised technique for dimensionality reduction.
Basic Idea Behind PCA
The basic idea behind PCA is to exploit the correlations between the original features. To understand this, lets look at the following two plots showing how a pair of variables vary together. In the left plot, there is no relationship in how X-Y values are varying; the values seem to be varying randomly. On the other hand, the variations in the right side plot exhibits a pattern; the Y values are moving up in a linear fashion. In terms of correlation, we say that the values in the left plot show no correlation while the values in the right plot show good correlation. It is not hard to notice that given a X-value from the right plot, we can reasonably guess the Y-value; however this cannot be done for X-values in the left graph. This means that we can represent the data in the right plot with a good approximation lying along a line, that is we can reduce the original two-dimensional data in one dimensions. Thus achieving dimensionality reduction. Of course, such a reduction is not possible for data in the left plot where there is no correlation in X-Y pairs of values.
PCA Steps
Now that we know the basic idea behind the PCA, let's look at the steps needed to perform PCA. These are:
We start with N d-dimensionaldata vectors, $\boldsymbol{x}_i, i= 1, \cdots,N$, and find the eigenvalues and eigenvectors of the sample covariance matrix of size d x d using the given data
We select the top k eigenvalues, k ≤ d, and use the corresponding eigenvectors to define the linear transformation matrix A of size k x d for transforming original features into the new space.
Obtain the transformed vectors, $\boldsymbol{y}_i, i= 1, \cdots,N$, using the following relationship. Note the transformation involves first shifting the origin of the original feature space using the mean of the input vectors as shown below, and then applying the transformation.
$\boldsymbol{y}_i = \bf{A}(\bf{x}_i - \bf{m}_x)$
The transformed vectors are the ones we then use for visualization and building our predictive model. We can also recover the original data vectors with certain error by using the following relationship
The mean square error (mse) between the original and reconstructed vectors is the sum of the eigenvalues whose corresponding eigenvectors are not used in the transformation matrix A.
Another way to look at how good the PCA is doing is by calculating the percentage variability, P, captured by the eigenvectors corresponding to top k eigenvalues. This is expressed by the following formula
$ P = \frac{\sum\limits_{j=1}^k \lambda_j}{\sum_{j=1}^d \lambda_j}$
A Simple PCA Example
Let's look at PCA computation in python using 10 vectors in three dimensions. The PCA calculations will be done following the steps given above. Lets first describe the input vectors, calculate the mean vector and the covariance matrix.
Next, we get the eigenvalues and eigenvectors. We are going to reduce the data to two dimensions. So we form the transformation matrix A using the eigenvectors of top two eigenvalues.
With the calculated A matrix, we transform the input vectors to obtain vectors in two dimensions to complete the PCA operation.
Looking at the calculated mean square error, we find that it is not equal to the smallest eigenvalue (0.74992815) as expected. So what is the catch here? It turns out that the formula used in calculating the covariance matrix assums the number of examples, N, to be large. In our case, the number of examples is rather small, only 10. Thus, if we multiply the mse value by N/(N-1), known as the small sample correction, we will get the result identical to the smallest eigenvalue. As N becomes large, the ratio N/(N-1) approaches unity and no such correction is required.
The above PCA computation was deliberately done through a series of steps. In practice, the PCA can be easily done using the scikit-learn implementation as shown below.
Before wrapping up, let me summarize a few takeaways about PCA.
You should not expect PCA to provide much reduction in dimensionality if the original features have little correlation with each other.
It is often a good practice to perform data normalization prior to applying PCA. The normalization converts each feature to have a zero mean and unit variance. Without normalization, the features showing large variance tend to dominate the result. Such large variances could also be caused by the scales used for measuring different features. This can be easily done by using sklearn.preprocessing.StandardScalar class.
Instead of performing PCA using the covariance matrix, we can also use the correlation matrix. The correlation matrix has a built-in normalization of features and thus the data normalization is not needed. Sometimes, the correlation matrix is referred to as the standardized covariance matrix.
Eigenvalues and eigenvectors are typically calculated by the singular value decomposion (SVD) method of matrix factorization. Thus, PCA and SVD are often viewed the same. But you should remember that the starting point for PCA is a collection of data vectors that are needed to compute sample covariance/correlation matrices to perform eigenvector decomposition which is often done by SVD.






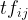 . The document frequency of word i represents the number of documents in the corpus with word i in them. Let us represent document frequency for word i by
. The document frequency of word i represents the number of documents in the corpus with word i in them. Let us represent document frequency for word i by 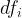 . With N as the number of documents in the corpus, the tf-idf weight
. With N as the number of documents in the corpus, the tf-idf weight 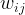 for word i in document j is computed by the following formula:
for word i in document j is computed by the following formula:

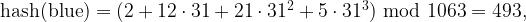
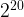 ;
however, you can specify the size if the corpus is not exceedingly
large. The result of applying HashingVectorizer to our example corpus is
shown below. You will note that the parameter n_features,
which determines the hash table size, is set to 6. This has been done to
show collisions since our corpus has 7 distinct words after filtering
stop words.
;
however, you can specify the size if the corpus is not exceedingly
large. The result of applying HashingVectorizer to our example corpus is
shown below. You will note that the parameter n_features,
which determines the hash table size, is set to 6. This has been done to
show collisions since our corpus has 7 distinct words after filtering
stop words.



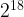 or more seems to give good performance. While this size might appear
large, some comparative numbers illuminate the advantage of feature
hashing. For example, an
or more seems to give good performance. While this size might appear
large, some comparative numbers illuminate the advantage of feature
hashing. For example, an 



