Canonical Correlation Analysis (CCA) is a powerful statistical technique. In machine learning and multimedia information retrieval, CCA plays a vital role in uncovering intricate relationships between different sets of variables. In this blog post, we will look into this powerful technique and show how it can be used for finding hidden correlations as well as for dimensionality reduction.
To understand CCA's capabilities, let’s take a look at two sets of observations, X and Y, shown below. These two sets of observations are made on the same set of objects and each observation represents a different variable.
 |
| Two Sets of Observations |
When computing the pairwise correlation between the column vectors of X and Y, we obtain the following set of values, where the entry at (i,j) represents the correlation between the i-th column of X and the j-th column of Y.
 |
The resulting correlation values give us some insight between the two sets of measurements. The correlation values show moderate to almost no correlation between the columns of the two datasets except a relatively higher correlation between the second column of X and the third column of Y.
Hidden Relationship
It looks like there is not much of a relationship between X and Y. Is that so? Let's wait before concluding that X and Y do not have much of a relationship.
Lets transform X and Y into one-dimensional arrays, a and b, using the vectors [-0.427 -0.576 0.696] and [0 0 -1].
a = X[-0.427 -0.576 0.696]T
b = Y[0 0 -1]T
Now, let's calculate the correlation between a and b. Wow! we get a correlation value of 0.999, meaning that the two projections of X and Y are very strongly correlated. In other words, there is a very strong hidden relationship present in our two sets of observations. Wow! How did we end up getting a and b?” The answer to this is the canonical correlation analysis.
What is Canonical Correlation Analysis?
Canonical correlation analysis is a technique that looks for pairs of basis vectors for two sets of variables X and Y such that the correlation between the projections of X and Y onto these basis vectors are mutually maximized. In other words, the transformed arrays show much higher correlation to bring out any hidden relationship. The number of pairs of such basis vectors is limited to the smallest dimensionality of X and Y. For example, if X is an array of size nxp and Y of size nxq, then the number of basis vectors cannot exceed min{p,q}.
Assume wx and wy be the pair of basis vectors projecting X and Y into a and b given by a=Xwx, and b=Ywy. The projections a and b are called the scores or the canonical variates. The correlation between the projections, after some algebraic manipulation, can be expressed as:
$\Large \rho = \frac{\bf{w}_{x}^T \bf{C}_{xy}\bf{w}_{y}}{\sqrt{\bf{w}_{x}^T \bf{C}_{xx}\bf{w}_{x}\bf{w}_{y}^T \bf{C}_{yy}\bf{w}_{y}}}$,
where Cxx, Cxy and Cyy are three covariance matrices. The canonical correlations between X and Y are found by solving the eigenvalue equations
$ \bf{C}_{xx}^{-1}\bf{C}_{xy}\bf{C}_{yy}^{-1}\bf{C}_{yx}\bf{w}_x = \rho^2 \bf{w}_x$
$ \bf{C}_{yy}^{-1}\bf{C}_{yx}\bf{C}_{xx}^{-1}\bf{C}_{xy}\bf{w}_y = \rho^2 \bf{w}_y$
The eigenvalues in the above solution correspond to the squared canonical correlations and the corresponding eigenvectors yield the needed basis vectors. The number of non-zero solutions to these equations are limited to the smallest dimensionality of X and Y.
CCA Example
Let’s take a look at an example using the wine dataset from the sklearn library. We will divide the13 features of the dataset into X and Y sets of observations. The class labels in our example will act as hidden or latent feature. First, we will load the data, split it into X and Y and perform feature normalization.
from sklearn.datasets import load_wine
import numpy as np
wine = load_wine()
X = wine.data[:, :6]# Form X using first six features
Y = wine.data[:, 6:]# Form Y using the remaining seven features
# Perform feature normalization
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
Y = scaler.fit_transform(Y)Next, we import CCA object and fit the data. After that we obtain the canonical variates. In the code below, we are calculating 3 projections, X_c and Y_c, each for X and Y.
from sklearn.cross_decomposition import CCA
cca = CCA(n_components=3)
cca.fit(X, Y)
X_c, Y_c = cca.transform(X, Y)cca_corr = np.corrcoef(X_c.T, Y_c.T).diagonal(offset=3)
print(cca_corr)[0.90293514 0.73015495 0.51667522]
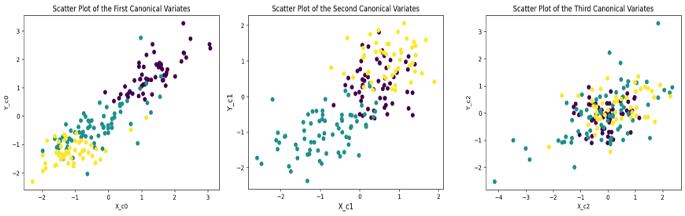
The highest canonical correlation value is 0.9029, indicating a strong hidden relationship between the two sets of vectors. Let us now try to visualize whether these correlations have captured any hidden relationship or not. In the present example, the underlying latent information not available to CCA is the class-membership of different measurements in X and Y. To check this, I have plotted the scatter plots of the three sets of x-y canonical variates where each variate pair is colored using the class label not accessible to CCA. These plots are shown below. It is clear that the canonical variates associated with the highest correlation coefficient show the existence of three groups in the scatter plot. This means that CCA is able to discern the presence of a hidden variable that reflects the class membership of the different observations.
 |
Summary
Canonical Correlation Analysis (CCA) is a valuable statistical technique that enables us to uncover hidden relationships between two sets of variables. By identifying the most significant patterns and correlations, CCA helps gain valuable insights with numerous potential applications. CCA can be also used for dimensionality reduction. In machine and deep learning, CCA has been used for cross-modal learning and cross-modal retrieval.




